Discover how VLMs are revolutionizing the way machines understand and interact with visual content
Introduction
Imagine an AI system that can not only see an image but also understand it, describe it, answer questions about it, and even engage in meaningful conversations about what it observes. This isn’t science fiction anymore—it’s the reality of Vision Language Models (VLMs), one of the most exciting frontiers in artificial intelligence today.
VLMs represent a groundbreaking convergence of computer vision and natural language processing, creating systems that can bridge the gap between what machines see and what they understand. Let’s explore how these models work, what makes them powerful, and why they’re transforming industries across the globe.
What Are Vision Language Models?
Vision Language Models are sophisticated AI systems that combine two traditionally separate domains: computer vision (the ability to process and analyze visual data) and natural language processing (the ability to understand and generate human language). By merging these capabilities, VLMs can process images or videos alongside text, enabling them to perform tasks that require understanding both modalities simultaneously.
Think of VLMs as AI systems with both eyes and a voice—they can observe visual content and communicate about what they see in natural, human-like language.
The Core Components
Every VLM is built on two fundamental pillars:
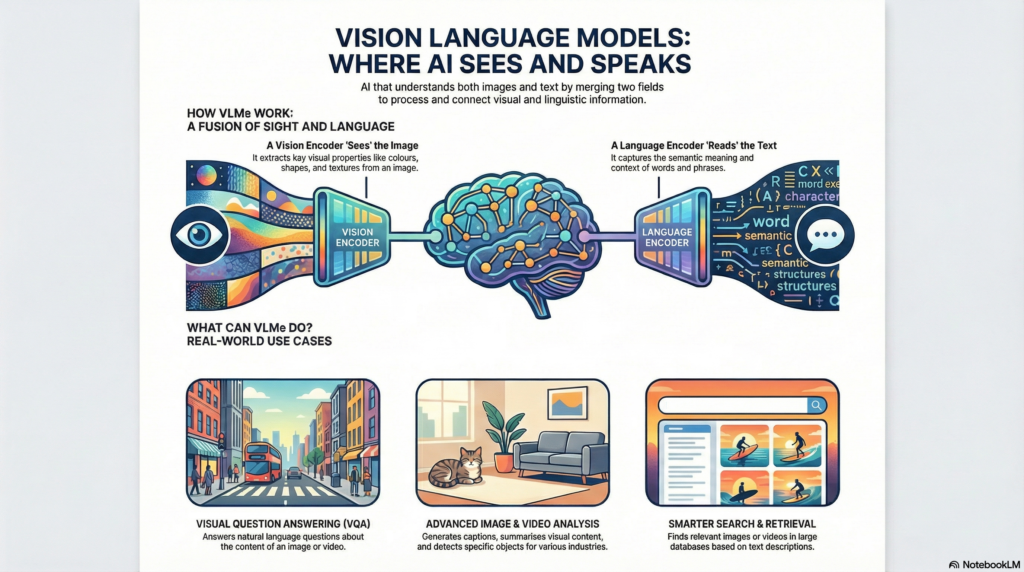
1. The Vision Encoder
The vision encoder acts as the model’s “eyes,” extracting crucial visual information from images or videos. Early VLMs used convolutional neural networks for this purpose, but modern systems have evolved to use Vision Transformers (ViT). These advanced encoders break images into patches and process them as sequences, similar to how language models process words, capturing colors, shapes, textures, and spatial relationships.
2. The Language Encoder
The language encoder serves as the model’s “linguistic brain,” understanding the semantic meaning of text and converting it into mathematical representations that machines can process. Most VLMs leverage transformer architectures—the same technology powering ChatGPT and other large language models—to handle this component. These encoders use self-attention mechanisms to focus on the most relevant parts of text input, understanding context and relationships between words.
How VLMs Learn: Training Strategies
Training a VLM is like teaching a child to connect words with pictures, but at an exponentially more complex scale. Several sophisticated techniques make this possible:
Contrastive Learning
This approach teaches VLMs to understand which images match which text descriptions. The model learns by seeing millions of image-caption pairs and figuring out which combinations belong together. For instance, CLIP (Contrastive Language-Image Pretraining) was trained on 400 million image-caption pairs from the internet, enabling it to understand visual concepts it had never explicitly been taught.
Masking Techniques
Similar to filling in blanks in a test, masking involves hiding parts of either the text or image and asking the model to predict what’s missing. This forces the VLM to develop a deep understanding of the relationship between visual and textual information.
Generative Model Training
Some VLMs learn by creating new content—either generating images from text descriptions or producing detailed text descriptions from images. This bidirectional training strengthens the model’s understanding of both modalities.
Building on Pretrained Models
Rather than starting from scratch, many modern VLMs leverage existing, powerful models as building blocks. For example, LLaVA combines the pretrained CLIP vision encoder with the Vicuna language model, using a simple projection layer to align their outputs.
Real-World Applications: Where VLMs Shine
VLMs aren’t just theoretical constructs—they’re solving real problems across diverse industries:
Healthcare and Medical Imaging
VLMs can analyze medical scans and provide detailed descriptions, helping radiologists identify abnormalities more quickly. They can answer questions like “Are there any signs of pneumonia in this chest X-ray?” providing both visual analysis and contextual medical knowledge.
Manufacturing and Quality Control
In production facilities, VLMs monitor equipment through video feeds, identifying potential defects or maintenance needs in real-time. They can examine images of manufactured parts and provide instant feedback on quality standards.
E-commerce and Retail
Online shoppers can now search using natural language queries like “show me red dresses with floral patterns” and VLMs will retrieve relevant images from vast catalogs. This technology also powers virtual try-on features and product recommendation systems.
Autonomous Systems and Robotics
Self-driving vehicles and robots use VLMs to understand their environment and respond to visual instructions. A robot equipped with a VLM can be told “pick up the blue box on the left shelf” and execute the task by understanding both the visual scene and the linguistic command.
Content Creation and Accessibility
VLMs generate image captions and descriptions automatically, making visual content accessible to people with visual impairments. They also assist content creators by generating detailed descriptions for SEO, social media, and documentation purposes.
Education and Research
Students and researchers can upload diagrams, charts, or scientific images and ask questions about them. VLMs can explain complex visual data, identify patterns, and provide educational context.
Leading VLMs: The Current Landscape
The VLM space is evolving rapidly, with several standout models leading the charge:
GPT-4o from OpenAI represents a unified approach, processing audio, vision, and text within a single neural network. It can handle mixed inputs and produce versatile outputs, making it highly flexible.
Gemini 2.0 Flash from Google supports multiple input modalities including audio, images, text, and video, with image generation capabilities on the horizon.
Llama 3.2 from Meta offers open-source vision-language variants with 11 and 90 billion parameters, democratizing access to advanced VLM technology.
DeepSeek-VL2 provides an efficient open-source option with variants ranging from 1 to 4.5 billion parameters, making VLMs more accessible to smaller organizations and researchers.
Measuring Success: VLM Benchmarks
How do we know if a VLM is performing well? The AI community has developed several specialized benchmarks:
- MathVista tests visual mathematical reasoning abilities
- MMMU (Massive Multidiscipline Multimodal Understanding) evaluates knowledge across various subjects
- OCRBench assesses text recognition and extraction capabilities
- VQA (Visual Question Answering) challenges models to answer open-ended questions about images
These benchmarks ensure VLMs meet rigorous standards before deployment in critical applications.
Challenges and Considerations
Despite their impressive capabilities, VLMs face several significant challenges:
Bias and Fairness
VLMs can inherit biases present in their training data, potentially leading to unfair or discriminatory outputs. Addressing this requires diverse training datasets and ongoing monitoring.
Hallucinations
Like their text-only LLM counterparts, VLMs sometimes generate incorrect or fabricated information about images. Validation and human oversight remain essential.
Computational Costs
Training and deploying VLMs requires substantial computing resources, making them expensive to develop and scale. Organizations must carefully balance performance needs with resource constraints.
Generalization
VLMs may struggle with edge cases or unusual image-text combinations they haven’t encountered during training. Continuous improvement through zero-shot learning and diverse datasets helps address this limitation.
The Future of VLMs
Vision Language Models represent more than just another AI advancement—they’re fundamentally changing how machines interact with the visual world. As these models become more sophisticated, efficient, and accessible, we’ll see them integrated into more aspects of daily life, from smart home devices to professional tools.
The convergence of vision and language understanding brings us closer to AI systems that can truly comprehend the world as humans do, opening possibilities we’re only beginning to imagine. Whether you’re a developer looking to build the next generation of applications, a business leader exploring AI integration, or simply someone curious about technology’s future, understanding VLMs is increasingly essential.
As we continue to refine these models, address their limitations, and expand their capabilities, one thing is certain: Vision Language Models are not just seeing the future—they’re helping us describe it, understand it, and shape it.
Getting Started with VLMs
For those interested in exploring VLMs:
- Experiment with existing models: Try GPT-4o, Gemini, or open-source options like Llama 3.2
- Explore datasets: Check out ImageNet, COCO, and LAION for training data
- Learn the fundamentals: Understand transformer architectures and computer vision basics
- Join the community: Engage with researchers and developers through platforms like Hugging Face
- Start small: Begin with pretrained models and fine-tune them for specific use cases
The era of machines that can truly see and understand is here, and Vision Language Models are leading the way.