In the rapidly evolving world of artificial intelligence, one technology has emerged as a critical infrastructure component: vector databases. As enterprises race to deploy generative AI applications, understanding how vector databases work—and why they matter—has become essential.
What Makes Vector Databases Different?
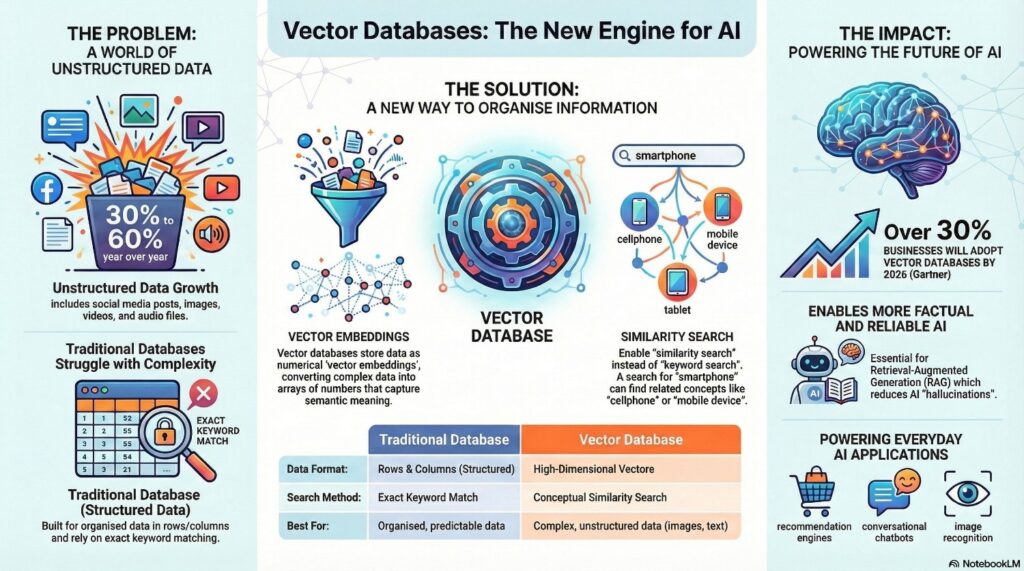
Traditional databases organize information in rows and columns, a structure that works beautifully for structured data like customer records or financial transactions. Vector databases take a fundamentally different approach. They store data as high-dimensional vectors—arrays of numbers that represent complex information like text, images, or audio in mathematical form.
This distinction isn’t merely technical. It represents a paradigm shift in how we handle the explosion of unstructured data that defines our digital age. Social media posts, images, videos, and audio clips are growing at rates between 30% and 60% annually, and traditional databases struggle to manage this tsunami of information efficiently.
The Mathematics of Meaning
At the heart of vector databases lies a powerful concept: vector embeddings. These numerical representations convert diverse data types into arrays that machine learning models can process. Think of embeddings as a universal translator that converts words, images, and sounds into a common mathematical language.
Consider a simple example with words. “Car” and “vehicle” have similar meanings but different spellings. In a vector space, their representations would be positioned close together, capturing their semantic relationship. A vector for “cat” might look like [0.2, -0.4, 0.7], while “dog” becomes [0.6, 0.1, 0.5]. The proximity of these vectors reflects the real-world relationship between these concepts.
This mathematical representation enables something traditional keyword searches cannot: true similarity search. When you search for “smartphone,” a vector database can intelligently return results for “cellphone” and “mobile device” because it understands semantic relationships, not just exact matches.
Three Core Functions
Vector databases serve three critical roles in AI applications:
Vector Storage: The database stores vector embeddings along with metadata like titles, descriptions, and data types. This structured storage enables rapid retrieval when an AI model needs relevant information.
Vector Indexing: To accelerate searches through vast high-dimensional spaces, vector databases create sophisticated indexes using algorithms like hierarchical navigable small world (HNSW) or locality-sensitive hashing (LSH). These techniques organize vectors into efficient tree-like or hash-based structures that dramatically speed up similarity searches.
Similarity Search: When a user queries an AI system, the model converts that query into a vector and searches for nearby vectors in the database. Using distance calculations and similarity metrics, the database returns the most relevant results in milliseconds.
Why Enterprises Are Adopting Vector Databases
According to Gartner, more than 30% of enterprises will have adopted vector databases by 2026 to build foundation models with relevant business data. This rapid adoption stems from several compelling advantages:
Vector databases deliver the speed and performance that generative AI applications demand. By indexing vectors and using approximate nearest neighbor searches, they can query datasets containing billions of data points within milliseconds. They scale horizontally, maintaining performance as both data volumes and query demands increase.
The cost benefits are significant too. Faster data retrieval means faster model training, reducing computational expenses. Built-in features for updating and inserting new data simplify data management compared to wrestling unstructured content into traditional database formats.
Perhaps most importantly, vector databases provide flexibility. They handle the complexity of images, videos, and multidimensional data with ease, making them ideal for diverse AI applications from chatbots to recommendation engines.
Real-World Applications
The practical applications of vector databases span across industries and use cases:
Retrieval-Augmented Generation (RAG): This AI framework enables large language models to retrieve facts from external knowledge bases, grounding AI responses in reliable, current information. Vector databases provide the efficient storage and retrieval mechanism that makes RAG implementations practical at scale. This helps reduce model hallucinations by anchoring responses in trusted data.
Conversational AI: Virtual agents and chatbots use vector databases to efficiently parse knowledge bases, providing contextual answers to user queries in real-time, often with source citations.
Recommendation Systems: E-commerce platforms represent customer preferences and product attributes as vectors, enabling personalized suggestions based on similarity to past purchases and browsing behavior.
Semantic Search: Moving beyond keyword matching, vector search enables users to find information based on meaning and context, dramatically improving search accuracy and user experience.
Choosing the Right Approach
Organizations have multiple options when implementing vector database capabilities. Stand-alone solutions like Pinecone offer dedicated vector database services, while open-source options like Weaviate and Milvus provide flexibility and customization. Some enterprises prefer data lakehouses with integrated vector capabilities, like IBM watsonx.data, while others add vector extensions to existing databases using tools like PostgreSQL’s pgvector.
The key is viewing vector databases not as isolated tools but as components within a broader data and AI ecosystem. Integration with existing data infrastructure, proper governance, and security measures are essential to ensure the data used to train models can be trusted.
Considerations and Limitations
While powerful, vector databases aren’t universal solutions. They excel at fact-based querying and similarity searches but may not be optimal for tasks requiring comprehensive topic summaries, where different indexing approaches might perform better.
Vector databases typically provide approximate results rather than exact matches. For applications requiring perfect accuracy, alternative database types might be necessary, accepting slower processing speeds as a trade-off.
The Road Ahead
As AI continues its transformation of business operations, vector databases will play an increasingly central role. They represent the critical infrastructure layer that makes modern AI applications practical at enterprise scale, bridging the gap between unstructured data and the mathematical models that power artificial intelligence.
For organizations embarking on AI initiatives, understanding vector databases isn’t just about keeping pace with technology—it’s about unlocking the full potential of their data in an AI-driven world. Whether powering recommendation engines, enabling sophisticated chatbots, or supporting retrieval-augmented generation, vector databases have become the hidden engine driving the AI revolution.
The future of AI depends on efficient, scalable access to diverse data types. Vector databases provide the foundation that makes that future possible.