
In the world of high-stakes data engineering, a pipeline is less like a simple script and more like a sprawling industrial assembly line. If one gear slips or a single component is misaligned, the entire floor grinds to a halt. This “precisely coordinated” chaos—where a minor extraction error at 2:00 AM can derail downstream models and lead to a cascade of corrupted dashboards—is the nightmare every data professional seeks to wake up from. The Directed Acyclic Graph (DAG) is the elegant architectural solution to this problem, providing the blueprint that transforms fragile, linear processes into resilient, automated systems.
The “No-Return” Policy: Why Acyclicity is a Pipeline’s Best Friend
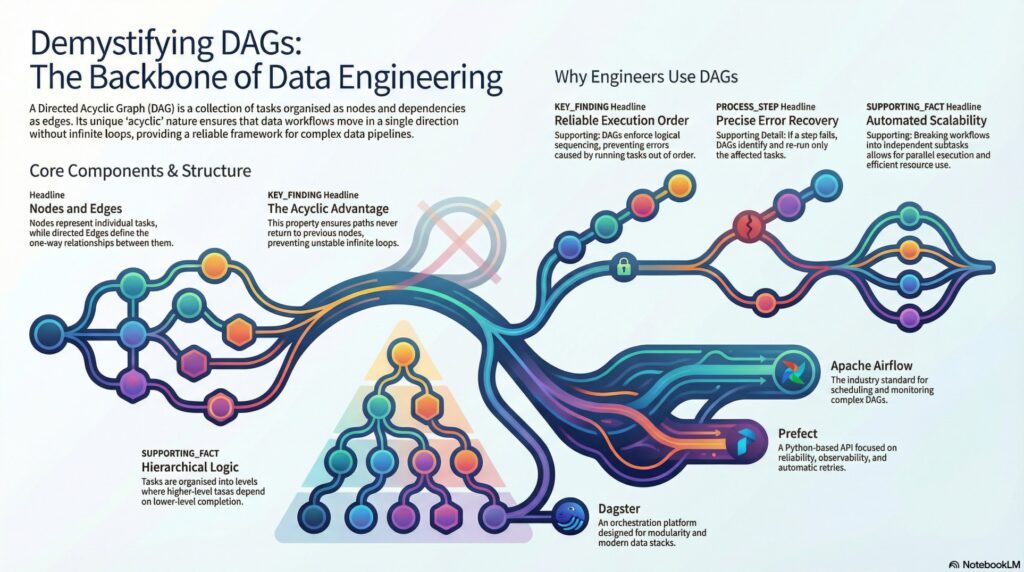
At its core, a DAG is a non-linear map of your data’s journey. It is composed of nodes, which we can think of as discrete functional checkpoints or units of work, and edges, the directed pathways that define how data flows between them.
While a standard graph might allow connections to loop back on themselves, the “Acyclic” nature of a DAG enforces a strict one-way relationship. This is the fundamental safeguard of data engineering. In a DAG, if Task A leads to Task B, there is no possible path for Task B to loop back and trigger Task A again. By eliminating the risk of infinite loops and recursive dependencies, DAGs ensure system stability and a predictable execution order.
“The acyclic nature of DAGs is one of the key characteristics that makes them ideal for data pipelines. They ensure that tasks can be executed without infinite loops or recursive dependencies that can result in system instability.”
Efficiency Through Modularity and Parallelism
The brilliance of the DAG lies in its ability to decompose monolithic, “black box” scripts into smaller, independent subtasks. When you break a pipeline into modular nodes, you grant your orchestrator the intelligence to see which tasks are truly dependent and which are free to run.
This modularity is the gateway to parallel execution. In modern cloud environments, where time is literally money, DAGs allow you to distribute independent workloads across multiple cores or machines simultaneously.
Interestingly, this logic isn’t just for the pipelines you build manually. One “aha!” moment for many engineers is realizing that Apache Spark utilizes DAGs internally. Even if a user doesn’t explicitly define a graph, Spark’s engine builds an internal DAG to optimize transformations, ensuring that data processing is as cost-effective and efficient as possible before the first byte is even moved.
Resilience by Design: The Art of the Partial Re-run
In a traditional linear script, a failure at step 99 typically requires you to restart from step one. DAGs offer a more sophisticated alternative: the partial re-run. Because a DAG tracks explicit dependencies and data intervals—the specific window of time or slice of data a run is responsible for—it can identify the exact “blast radius” of a failure.
If a single node fails, the orchestrator stops only the affected downstream branches. Once the issue is resolved, you don’t need to waste resources re-extracting data; you simply re-run the failed checkpoint and its successors. This targeted recovery saves hours of compute time and human effort, making the DAG the ultimate insurance policy for complex workflows.
The DAG as a Universal Language for Stakeholders
Beyond the code, the DAG serves as a vital communication bridge. The visual representation of a graph provides an immediate, intuitive map of the entire data lifecycle. This visual clarity allows technical teams to sit down with non-technical stakeholders and explain exactly where a metric comes from or why a specific delay occurred.
It is important to distinguish a DAG from a standard flowchart. While a flowchart describes general decision logic and “if-then” scenarios, a DAG is a rigorous map of execution dependencies. Modern orchestrators even enhance this map with Sensors—specialized nodes that wait for external triggers, such as the arrival of a file in an S3 bucket—allowing the graph to respond to real-time data events while maintaining its structured execution order.
Practical Spotlight: Orchestration in Action (Airflow)
Apache Airflow has become the industry standard for turning these graph concepts into reality. In Airflow, you define your logic in Python, using operators to establish the flow.
# Defining task dependencies in Apache Airflow
task1 = BashOperator(
task_id='extract_data',
bash_command='python extract.py'
)
task2 = BashOperator(
task_id='transform_data',
bash_command='python transform.py'
)
# The >> operator defines the dependency: task2 waits for task1
task1 >> task2
In this framework, every execution of your graph is a DAG Run. These runs track the status of every node, managing retries and logging failures at the individual task level, which provides the granular observability required for professional data operations.
The Modern Toolbox: Choosing Your Orchestrator
While Airflow is a pioneer, the ecosystem has expanded with specialized tools designed for different architectural needs:
• Apache Airflow: The versatile veteran, beloved for its expansive UI and robust community support in scheduling and monitoring.
• Prefect: A modern orchestrator focusing on “negative engineering” (handling failures), offering high observability and automatic retries.
• Dask: A powerhouse for Python users needing to parallelize complex computations across distributed clusters using a DAG model.
• Kubeflow Pipelines: The go-to choice for machine learning engineers running containerized workflows on Kubernetes.
• Dagster: A modular orchestrator that prioritizes type safety and local development, integrating deeply with modern tools like dbt and Snowflake.
Conclusion: Beyond the Pipeline
Adopting the DAG isn’t just a technical upgrade; it represents a cultural shift in how we approach data reliability. It is a move away from the “hope for the best” philosophy of linear scripts toward a “resilience by design” mindset.
As you evaluate your current data architecture, ask yourself: Is your system a fragile chain of dominoes, or is it a resilient, self-healing graph? Moving to a DAG-based orchestration model is more than just choosing a new tool—it is adopting the fundamental blueprint for reliable automation in the modern era.NotebookLM can be inaccurate; please double-check its responses.
🚀 Join the Community & Stay Connected
If you found this article helpful and want more deep dives on AI, software engineering, automation, and future tech, stay connected with me across platforms.
🌐 Websites & Platforms
- Main platform → https://pro.softwareengineer.website/
- Personal hub → https://kaundal.vip
- Blog archive → https://blog.kaundal.vip
🧠 Follow for Tech Insights
- X (Twitter) → https://x.com/k_k_kaundal
- Backup X → https://x.com/k_kumar_kaundal
- LinkedIn → https://www.linkedin.com/in/kaundal/
- Medium → https://medium.com/@kaundal.k.k
📱 Social Media
- Threads → https://www.threads.com/@k.k.kaundal
- Instagram → https://www.instagram.com/k.k.kaundal/
- Facebook Page → https://www.facebook.com/me.kaundal/
- Facebook Profile → https://www.facebook.com/kaundal.k.k/
- Software Engineer Community Group → https://www.facebook.com/groups/me.software.engineer
💡 Support My Work
If you want to support my research, open-source work, and educational content:
- Gumroad → https://kaundalkk.gumroad.com/
- Buy Me a Coffee → https://buymeacoffee.com/kaundalkkz
- Ko-fi → https://ko-fi.com/k_k_kaundal
- Patreon → https://www.patreon.com/c/KaundalVIP
- GitHub Sponsor → https://github.com/k-kaundal
⭐ Tip: The best way to stay updated is to bookmark the main site and follow on LinkedIn or X — that’s where new releases and community updates appear first.
Thanks for reading and being part of this growing tech community!
