
In the high-stakes world of time-series forecasting, anomalies are rarely binary. Whether you are managing global supply chains, financial markets, or public health data, you inevitably operate in a “gray area.” Is a sudden surge in COVID-19 cases a legitimate viral outbreak—a critical signal that must be preserved for downstream models—or is it merely a data glitch caused by a reporting delay?
Traditional detection systems are notoriously noisy, leading to “false alarm” fatigue that desensitizes operators to real threats. To solve this, we must move beyond simple observability—knowing what happened—to Agentic Decision Intelligence—deciding what to do about it. Our mission is to evolve from passive monitoring to an architecture that can orchestrate, mitigate, and govern data quality autonomously.
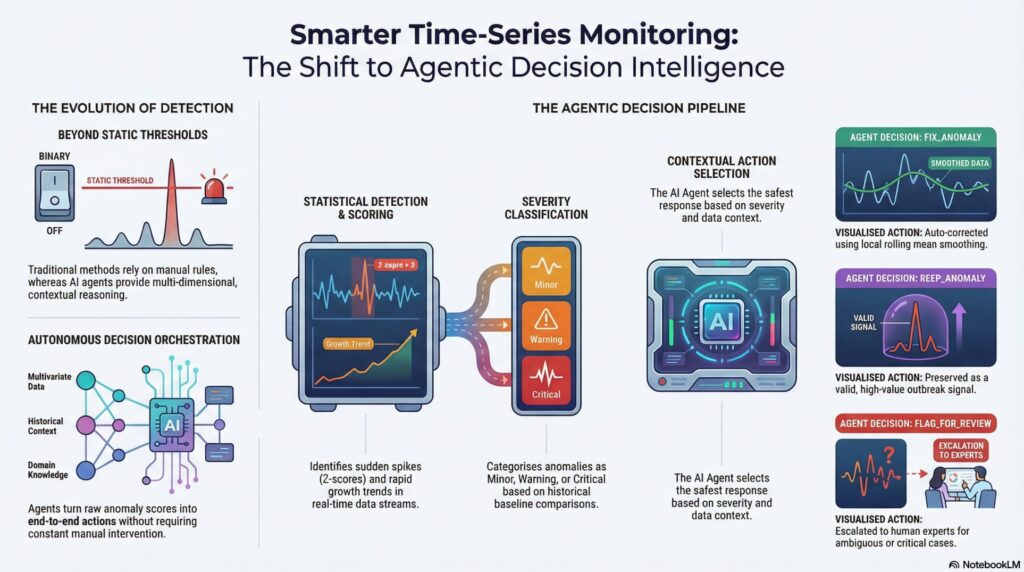
Architectural Blindness: Why Context is the Missing Link
Traditional statistical methods, such as Z-scores and Interquartile Range (IQR) thresholds, are mathematically correct but operationally blind. They identify deviations from a mean, but they lack the situational awareness required to understand the why behind the spike. They treat every data point outside a static boundary as an error, regardless of the underlying real-world regime shift.
As the source material notes, the limitations of the traditional pipeline are clear:
“[Traditional detection] works on static rules and manually sets thresholds… [with] no contextual reasoning.”
Contextual reasoning is the differentiator that transforms raw anomaly scores into actionable intelligence. Without it, your pipeline is just a series of filters; with it, it becomes a strategic asset capable of distinguishing between a reporting “hiccup” and a fundamental change in the data environment.
From Observability to Agentic Orchestration
The paradigm shift in modern operational AI is the transition from a passive pipeline to an AI Agent Orchestrator. In this model, the agent acts as a “first line of defense,” sitting between the detection algorithm and the production environment. Its role is to prevent performance damage—such as corrupted downstream training sets or skewed executive dashboards—by autonomously managing the lifecycle of an anomaly.
The agent is empowered to execute three specific autonomous actions:
• FIX_ANOMALY: Correct the data point if it is identified as localized reporting noise.
• KEEP_ANOMALY: Preserve the data point as a valid, high-integrity signal (e.g., a viral moment).
• FLAG_FOR_REVIEW: Escalate ambiguous or high-severity cases for human intervention.
By delegating low-level data cleaning to an agent, we ensure that the “noise” never reaches the core model, allowing the system to scale without requiring a proportional increase in manual oversight.
The Severity Gate: Governing the Decision Boundary
To prevent “destructive auto-corrections” in high-impact scenarios, we implement a Severity Gate. This layer uses specific architectural thresholds to classify anomalies before the agent takes action. Crucially, growth is not measured in a vacuum; it is calculated against a 7-day rolling average (ROLLING_WINDOW) to establish a stable baseline.
| Severity Level | Growth Threshold (vs. 7-Day Baseline) | Impact Description |
|---|---|---|
| CRITICAL | ≥ 100% Increase | Explosive trend or sudden outbreak. |
| WARNING | ≥ 40% Increase | Sustained acceleration requiring monitoring. |
| MINOR | < 40% Increase | Likely localized noise or minor fluctuation. |
The Safety Governor: The system also employs a MIN_ABS_INCREASE of 500 cases. If the absolute growth falls below this floor, the anomaly is treated as negligible, regardless of the percentage. This dual-metric approach ensures the agent does not overreact to high growth rates in low-volume data environments.
The Power of the Autonomous “Auto-Correct”
When the agent triggers a FIX_ANOMALY action, it doesn’t just delete the point; it employs local rolling mean smoothing. By calculating the average of the immediate 3-day window preceding the spike, the agent “heals” the data, replacing the glitch with a statistically probable value.
To maintain the high-frequency requirements of modern pipelines, this reasoning must be instantaneous. By leveraging GroqCloud, the agent can perform low-latency LLM inference, ensuring that this “first line of defense” does not become a bottleneck in the data stream. As the source context highlights:
“This is agentic decision intelligence, not merely anomaly detection.”
The result is a self-healing pipeline that maintains data continuity without human friction.
The Safety Valve: Knowing When to Call a Human
Even the most sophisticated AI requires a “human-in-the-loop” safeguard. While the agent is excellent at filtering noise, it can occasionally suffer from “over-eagerness.”
In Scenario 3 of our technical evaluation, we observed a critical limitation: the agent auto-corrected a WARNING anomaly that actually represented a 40% growth spike—a legitimate signal of sustained acceleration. Because the agent prioritized “smoothing,” it effectively suppressed a real-world trend. This failure highlights the necessity of human review for “WARNING” and “CRITICAL” tiers. We must calibrate the decision boundary to ensure that automation handles the mundane noise while humans retain sovereignty over the signals that define the business.
The Future: Toward Self-Healing Data Ecosystems
The evolution of operational AI is moving away from simple alerting and toward comprehensive, decision-driven systems. By combining statistical rigour for detection with LLM-based reasoning for action, we are building systems that don’t just watch the data—they govern it.
The future of this architecture lies in:
• Multi-agent architectures to improve resilience and specialized reasoning.
• Enriched feature sets, incorporating external signals like hospitalization rates or vaccination records to provide the agent with a “wider lens.”
• ML-driven detection to replace static Z-scores with adaptive pattern recognition.
As we move toward these autonomous environments, the question for every technical leader is no longer how to detect a spike, but which parts of your data pipeline are ready to start thinking for themselves?
